
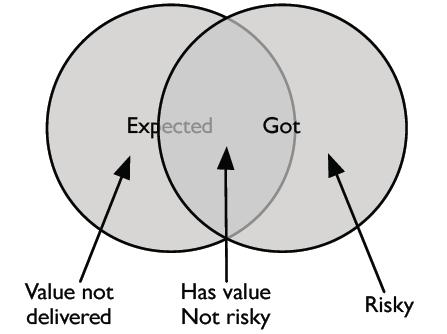
Last year, James Lyndsay introduced me to his “Nr1 diagram of testing” (© Workroom Productions): a deceivingly simple model that tries to capture the essence of testing.

The circle on the left represents our expectations – all the things we expect. This is the area where scripted tests or checklists come into play to tell us about the value that is present. The right hand circle represents the actual deliverable – what the software really does. This never completely matches what was originally expected, so this is where we use exploratory testing to find out about risk.
The diagram divides the world into four distinct regions:
- The overlap. These are the things we both expected and got.
- The region outside the circles. That is all we didn’t want, and didn’t receive in the end. A pretty infinite set, that is.
- The left-hand arc. This is what we expected to get, but didn’t receive. This means that the deliverable turned out less valuable than we had hoped.
- The right-hand arc. The software system under test does all kinds of things things we didn’t expect. There’s clearly some risk involved, here, and it’s up to us to discover just how much risk there is.
Simplicity is of course the main strength of such a model. It can certainly help to identify or classify things in our quest to quickly grasp the essence of things.
These four regions got me thinking. I’d like to expand on that. What about things that we expected and received, but do not prove value, for instance? Unneeded features – not too unrealistic. Or – even better – what about things that were not expected, but are there and actually do provide value in the end? Immediately the term “Collateral features” came to mind: no matter how hard we try to create designs for certain uses, people will always utilize them in their own way. These unintended uses can be strange sometimes, but some them are downright brilliant.
Take a look at Alec Brownstein. While most people use Google AdWords to promote their business (after all, that’s what it was designed for), Alec used it to get a job. He was trying to land a job as a copywriter with some of the top ad agencies in New York City. He assumed that the creative directors at these top agencies would “vanity google” their own name. So he bought AdWords of the names and put a special message in to each of them. The rest is history. He now works for Y&R, after a total investment of $6 (story here).
Collateral features also emerged in the microblogging world. Because Twitter provided no easy way to group tweets or add extra data, the twitter community came up with their own way: hashtags. A hashtag is similar to other web tags- it helps add tweets to a category. Hashtags weren’t an official feature, but they sure made their way into the daily twitter work lexicon of billions of people.
In an article in Forbes magazine called You Can’t Predict Who Will Change The World, Nassim Nicholas Taleb pointed out that things are all too often discovered by accident—but we don’t see that when we look at history in our rear-view mirrors. The technologies that run the world today (like the Internet, the computer and the laser) are not used in the way intended by those who invented them.
There will always be unforeseen usage of your software. Some prove risky, others do contain value. Some of these collateral features even replace the intended use to become main features and make their way in the ‘expected’ circle. Ultimately, your customers make the final call. They decide how to use your product or service. Not you, not your marketeers.
– “But no user would ever do that!”
– “Fair enough. Wanna bet?”

{kind=link}